構造推定で一番大事なのは反実仮想である。反実仮想をやるためにわざわざ複雑なステップを踏まなければならないのである。
バックワードに解くタイプの研究は、反実仮想以上のことは論文内で達成できないであろう。ここでは「トップジャーナルに載っている反実仮想=最高であると保証済の反実仮想アイデア」をまとめていく。
動学ゲーム推定
構造推定で一番大事なのは反実仮想である。反実仮想をやるためにわざわざ複雑なステップを踏まなければならないのである。
バックワードに解くタイプの研究は、反実仮想以上のことは論文内で達成できないであろう。ここでは「トップジャーナルに載っている反実仮想=最高であると保証済の反実仮想アイデア」をまとめていく。
動学ゲーム推定
推定された値を使った反実仮想ってどんなものがあるか。
とりあえず均衡が解けるコードは手元にある前提で考えよう。たとえば均衡を解くのが重たすぎるので解かない2stepとかの手法が提示されているが、反実仮想を「解く」となったら結局均衡を解く必要がある。
解けないモデルを作って均衡解かないタイプの反実仮想しているペーパーがパブリッシュされてるのも意外とあるので、このへんは事前に解ける手法でいくのがトレンドらしい。
均衡が解けるコードがあるということは、経済学的理論的に正しいData Generating Processが閉じた形で実装されていて、パラメタとエラー項を与えれば、ばらつきのあるシミュレーションデータが作れるということである。
また、提示したモデルが正しく真値を推定できているかどうかという計量理論的妥当性も確認ができる、ということである。
ただ90%の論文はこの点を検証しないままパブリケーションされているので、事後的にモデルの性能を検証できるかどうかはかなり微妙である。
また、解けるサンプルを関心のあるサブサンプルに絞ります、というのも、推定してるサンプルと解くサンプル違うじゃん、ランダムサンプリングじゃないとダメじゃん、という話もとりあえず未解決っぽいのでおいておく。
第一に、推定されたパラメタのうちひとつを2倍3倍に変えたりして同じモデルを解くとどういうアウトカムになるか、という設定。
例えば、需要推定された価格弾力性の値を二倍に変えてやると、市場のシェアはどうかわるか。
学校選択の需要が推定されたときに、たとえば距離のdisutilityを二倍にしてやると提出する選好ランキングはどうかわるか。
->このタイプは政策含意が分からなかったが、「model decomposition」としてモデルの挙動をみてやる、という解答をしている人がいてこれがいいと思った。
第二に、推定されたパラメタは同じ、だけどモデルのうち関心のある要素をひとつ大きく変えて、モデルを解くとどういうアウトカムになるか、という設定。
例えば、需要推定された価格弾力性は同じにするが、合併を外生的に起こして二商品が同じ企業にコントロールされるような状況になると、市場のシェアと価格設定はどう変わるか。
学校選択の需要が推定されたときに、たとえばなんか補助金が事前に与えられていた時にそれを0にするとどう提出する選好ランキングはどうかわるか。
->このタイプは政策含意が制度的情報から直結しているが、実際その要素動かせるのかどうか、という点は別に考える必要がある。すごいペーパーは、この要素を動かす主体の意思決定(例えば政府の支出最小化)なんかも考えてる。
第三に、推定されたパラメタは同じ、だけどモデルの構成要素自体を変えてしまう、という設定。
例えば、オークションの設定をfirst price sealed bidから2nd price sealed bidにメカニズムを変えるとどうアウトカムが変わるか
プレイヤーの選択肢集合自体を外生的に増やしてやるとか情報集合を変えてやるなどゲームの設定自体を変えるとどうアウトカムが変わるか
->メカニズム自体を識別する、という発想はまだ未開拓。というか、観察されるDGPとそれをもとに推定したパラメタを維持して、違うDGPを考えるというのがどこまで通るかというのはどこまで許されるのか分からない。
以下では構造推定のオンライン教材をまとめる。
構造推定やりたいんだけど、勉強の始め方が分からない、という言い訳はそろそろできなくなってしまいました。少なくとも、Ph.D. IO topic courseの一年分(3h*12weeks*2semesters)ぐらいのビデオレクチャーは出そろってきました。
AEAのContinuing EducationでSteveとPhilのIOのチュートリアルが見れる。需要推定、オークション、静学競争、動学競争をカバー。これに伊神さんのパートを加えたらYaleのIOの授業がオンラインで受けれることに。https://t.co/fsV4zoQeLH
— Kosuke Uetake (@Chanman_ECON) January 24, 2021
Yale(Berry, Haile)のIOはこっちで、
https://www.aeaweb.org/conference/cont-ed/2021-webcasts
Harvard, Northwestern (U Penn), Austin(Pakes, Nevo, Ackerberg)のIOはこっち。上にはない生産関数の話もAckerbergがしている。
https://www.aeaweb.org/conference/cont-ed/2017-webcasts
しかも、Nevoは21年冬に出る予定のIOハンドブックの需要推定のパートのレクチャーもしている。
あとメインの手法どころでウェブレクチャーがないものは、マッチングとネットワーク形成ぐらいでしょうか。
このあたりの手法の概観図は頭に入っていて、実装もそれなりにしてみたあとに、制度知識とデータセットの塩梅で使える(使いたい)手法を掘り下げていく、ハンドブックIO最新版とハンドブックEcon of Marketingを読む、というのが基本でしょうか。
ハンドブックIOって2021版はほぼ構造推定の教科書みたいな感じで、理論は2007版からの進展は入れないって方針なのかしら(wpがでてるチャプター見ると、比重が理論1:実証9ぐらい違う気がする。まあ2007版の比重は理論8:実証2ぐらいだったけども。
— にるそん (@ohtanilson) September 8, 2021
学部生向けにかみ砕いた構造推定のエッセンスは以下のような形が取れるようである。
今日が締め切りだつたこの宿題、提出後も食いついてくる珍しい学生さんがいて「reduced-formの定義って結局何なんですか?」「カルテルが存続した場合の供給の反実仮想をあえてreduced-formでやるならどんな関数形?」経済コンサルで今夏インターンするらしいので最適な準備になったかも https://t.co/yNQXapfG2P
— 伊神満 (@MitsuruIgami_JP) April 17, 2020
構造推定の論文一本をケーススタディのディスカッションとフォーマルな議論のレクチャーそれぞれ一回ずつの講義に分割するやつ、これまでのところうまくいっている気がする。構造推定の論文の各要素を細かく解説していくと本一冊分、授業何回分かになるというのは、伊神さんの本から学んだことである。
— Kohei Kawaguchi (@mixingale) October 8, 2021
日本語でどうしても学びたいならば、経済セミナー一択。
Welcome to ようこそ、殺し合いの螺旋へ!!

やあ (´・ω・`)ようこそ、バーボンハウスへ。
以下略。
上では最後をこうまとめていた。
1(+ドラ2)+3+2+0+2+5(-4+裏ドラ2)=13翻前後がベースライン、全部完結するまでは当然あがれませんが。
結果、想定したバッドエンドのパスに落ちている(「パラメタの下限しか識別できないじゃん」と分かった)ので、ある意味予定通り。これがバックワードでやってみた治験結果。イメージとしては数え役満を目指して、13翻以上を取る予定だった。引用してるジャーナルの論文たちが自分の中では最低15翻って感じ。マーケティングとか書き方とかいろいろあるにしろ。
遺言書としてほにゃイヤーペーパとして全部結果まとめてるし、結果をLatexに自動生成するコードも書いてるし、reproduceableにはしてきたし、どこまで翻が変わるでしょうかねえ。
とりあえず、結果とコードはgithubにpushして、指導教官のテクニカルなポイントの最終チェックを経て、ウン十万かけて英文校正に出して。一週間かけて修正して再校正お願いして、ページ制限はだいたい本文40pageなのでそれに合わせたり、細かい点を修正した。そして、WPにして、指導教官の薦めるジャーナルからfirst shotを打ったところである。
とりあえず、一個は閉じた。閉じることが一番大事。モデルの推定アルゴリズムが複雑かつ分割できない処理になる場合と、いわゆるpower setが理論で入るモデルの実装は気を付けようと思った。感触的には、ちょっとだけ結果の説明がクリアにできたので、1翻アップの14翻で、意外と指導教官のカウントと近い。素性を知ってる方はWPへのコメントお待ちしております。
とりあえず、JMPも同じ産業のWPより後の時代をやる予定。raw dataの打ち込みと前処理と制度知識からやってるが、効率的にプロジェクトマネジメントするすべをだいぶ共著から学んだので多少見通しが立ってる気がする。
描きたい反実仮想を具体的にイメージしよう。
Igami, M., & Uetake, K. (2020). Mergers, innovation, and entry-exit dynamics: Consolidation of the hard disk drive industry, 1996–2016. The Review of Economic Studies, 87(6), 2672-2702.
Abstractにまとめられた反実仮想の結果は以下。
the current rule-of-thumb policy, which stops mergers when three or fewer firms exist, strikes approximately the right balance between pro-competitive effects and value-destruction side effects in this dynamic welfare trade-off.
この答えを得るためにバックワードで順に組み立てていく。
1. 答えたい問い:investigate the balance between pro-competitive effects and value-destruction side effects in this dynamic welfare trade-off.
2. 答えたい反実仮想政策:CS+PS+FCと合計の厚生評価
(1) changing the threshold number of firms
(2) If the HDD industry were disappearing faster
(3) Optimal ex-post (“surprise”) policy
3. 最終的に示したい図: 論文内のFig6の異なるNでの厚生評価の図
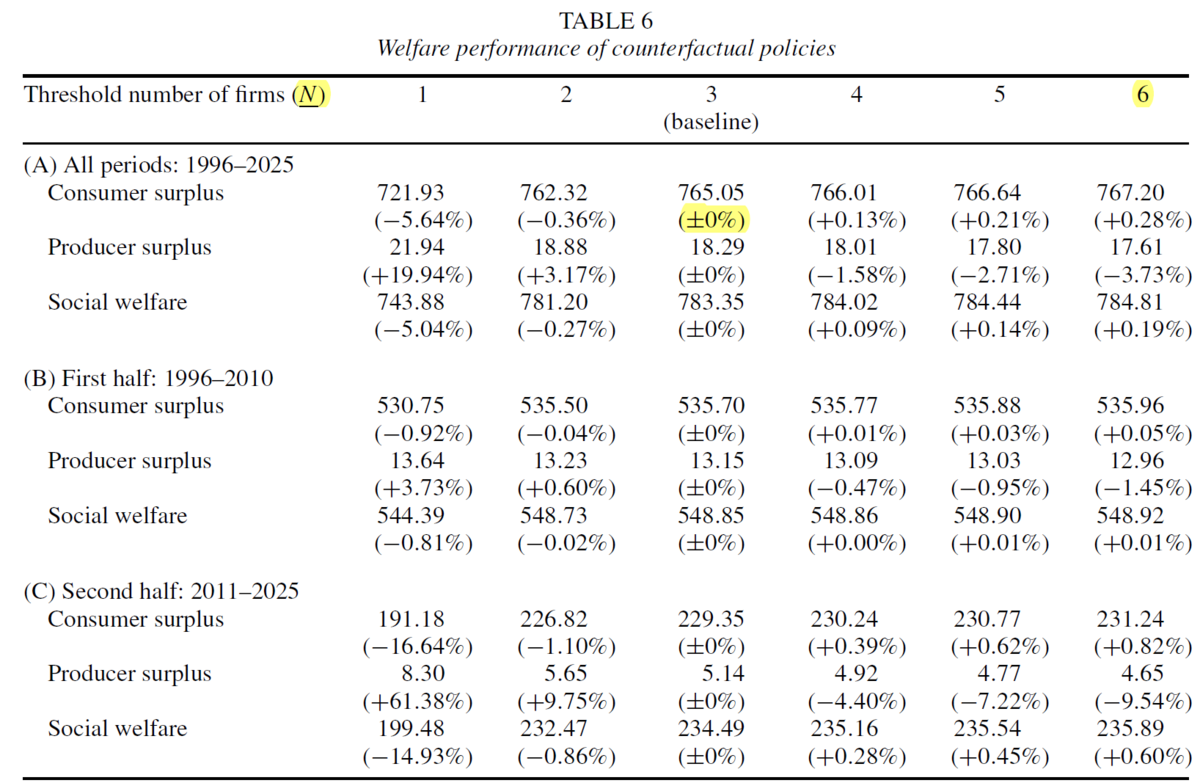
とTable 7のbyproductで得られる厚生評価以外の重要な均衡結果(企業数やイノヴェーションレベルや合併数)
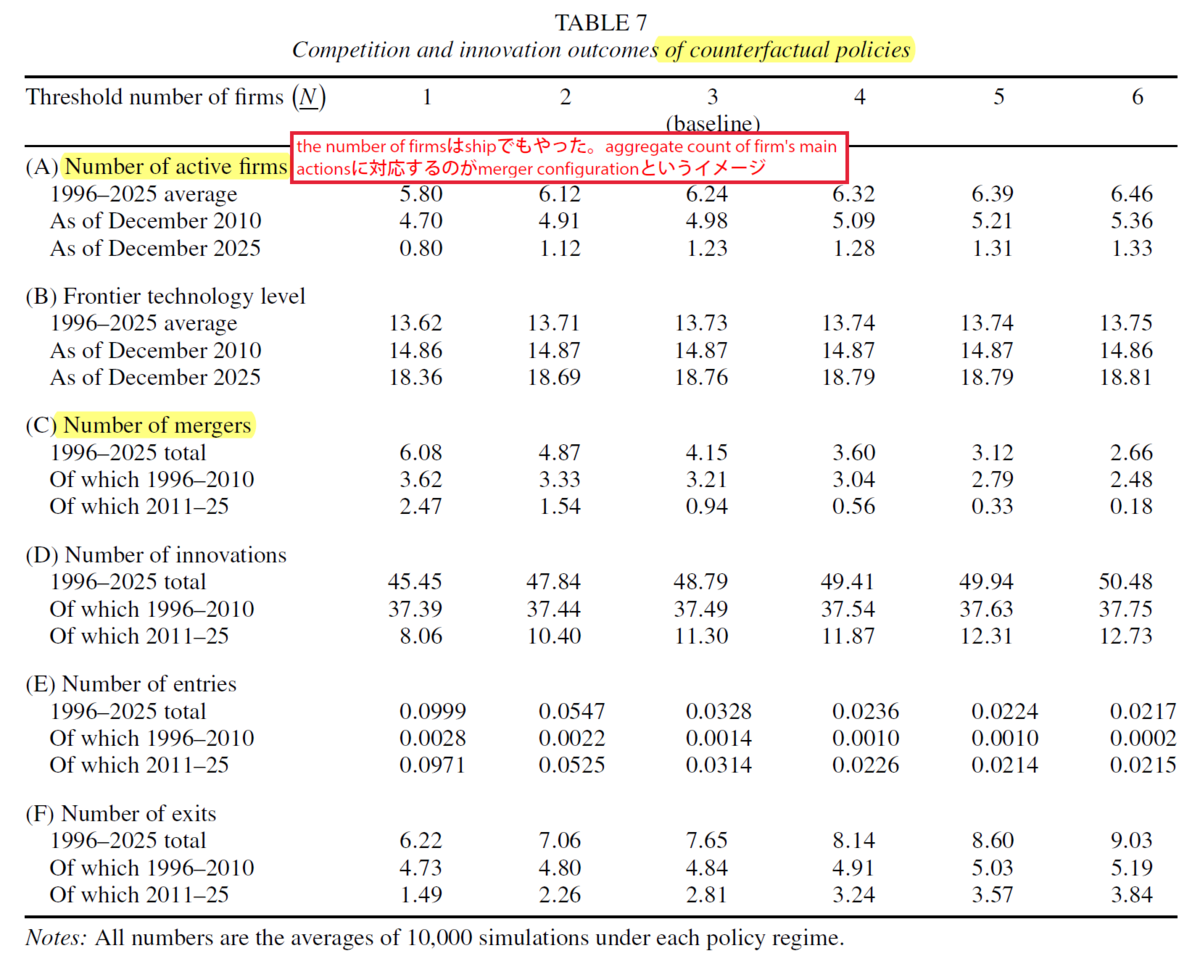
4. 問いに答えるためにモデルに入れたい要素(anecdotal evidenceとfeasibilityから考える):
(0). そもそも厚生評価するのでそれができる需要供給モデル選ぶ。
(1) changing the threshold number of firms: 反実仮想のmerger blockを入れて再計算すればいけそう。
(2) If the HDD industry were disappearing faster: demandが数年後にゼロに収束するとモデルに入れて、動学の再計算すればいけそう。
(3) Optimal ex-post (“surprise”) policy: 途中でmerger blockがスイッチする形で表現できそう。
描きたい反実仮想を具体的にイメージしよう。
Igami, M. (2018). Industry Dynamics of Offshoring The Case of Hard Disk Drives. American Economic Journal Microeconomics, 10(1), 67-101.
Abstractにまとめられた反実仮想の結果は以下。
build and estimate a dynamic offshoring game with entry/ exit to measure the benefits and costs of offshoring, investigate the
relationship between offshoring and market structure, and assess the
impacts of hypothetical government interventions
この答えを得るためにバックワードで順に組み立てていく。
1. 答えたい問い:investigate the relationship between offshoring and market structure,
2. 答えたい反実仮想政策:CS+PS+FCと合計の厚生評価
(1) No offshoring
(2) Unilateral US intervention
(3) Government Policies in Nash Equilibria
3. 最終的に示したい図: 論文内のFig7のY軸を企業数変化、X軸を時間にした図を描きたい。

Fig8のような国ごとの政策変更による厚生評価の変動を二国にしぼって印象的なプロットを描きたい。

4. 問いに答えるためにモデルに入れたい要素(anecdotal evidenceとfeasibilityから考える):
(0). そもそも厚生評価するのでそれができる需要供給モデル選ぶ。
(1). offshoring: offshoringという選択肢を持たない設定に変えてやればそう解釈できそうだが、offshoring costを4倍にしてやって解きなおす方法でもやれる。
(2).Unilateral US intervention:事後的にアメリカとそれ以外で分けて、アメリカのoffshoring costだけ4倍にして解きなおせばいけそう。
(3)Government Policies in Nash Equilibria: アメリカの(2)の動きに対応して、日本のoffshoring costも動かす。9grids * 9grids=81 scenariosで解きなおす外挿的なやり方でstrategicな要素を近似できそう。
構造推定における大きな障害のひとつは、一つの工程における計算スピードが全工程に伝播することである。
論文の分析工程自体は、章立てと同じく
- データの前処理と記述統計
- 誘導系的な分析と結果
- 構造推定モデルの記述
- 構造推定モデルの特定化と推定手法の記述
- 実データを使った構造推定モデルの結果
- 推定結果を元にした反実仮想
が本文に置かれる。また、本推定の前かAppendixに
- シミュレーションデータの生成過程の記述(=反実仮想の解き方でもある)
- シミュレーションデータの比較静学(=反実仮想がどう結果を出すかの記述でもある)
- 識別のチェック(点推定ならここはなくてもよいかも)
- シミュレーションデータでのfinite sampleでの推定精度検証(biasとRMSE)
が挿入される。
データの前処理と記述統計と誘導系の結果は、仮に前処理を調整するにしても数分で生データからLatexアウトプットまで終了するはずなので省略する。「構造推定モデルの記述」自体も、均衡の特徴づけと識別可能性までは紙とペンだけで完結するので、他パートと依存しない(紙とペンで完結しない場合はここにも作業が伝播する)
非常に面倒なのが、
- 構造推定モデルの特定化と推定手法の記述
から
- シミュレーションデータでのfinite sampleでの推定精度検証(biasとRMSE)
までのパートが「特定化」の変更の影響を反映する点である。例えば、X_1という変数に加えてX_2という変数を加えるという一見単純な追加処理も、コードが変数次元に自動で合わせる書き方になっていない限り、それなりの修正が必要になる。あるいは、より複雑な特定化の変更、例えば、行動経済学的な割引因子パラメタなどを追加で入れるとすると、そもそもそれが識別できるのかが研究者本人にもわからない。また、一般的にはmisspecification errorが必ず存在するので、エコノメ方面を推すのならばその頑健性をケアする必要がある。
ひとまず「信頼できる先行研究からわかっている絶対にうまくいく特定化、データ生成、推定」を再現してみて、その特定化にひとつずつ要素を加えていくというのが鉄則である(が、トップ5ですらそれが検証されていないケースもそれなりにあるし、だいたいOnline Appendix行きで、チェックする人も手法を使いたい数十人と厳密性にこだわる一部の流派なので世知辛い)。
特定化周りの工程は以下のような製造ライン(Julia AtomやRstudioのようなIDE、物理的なPCなどの作業環境)に分けるのが一つの効率化である。
0. 本推定の特定化を決める。
1. 特定化をもとにシミュレーションデータの生成過程の記述といくつか想定した環境を作るパラメタでデータセット生成
1.1. そのシミュレーションデータでの比較静学(構造パラメタを動かして挙動確認)
1.2. そのシミュレーションデータでの識別のチェックとfinite sampleでの推定精度検証
2. 本推定の特定化をもとに実データを使った構造推定モデルの推定
2.1. 推定結果のひとつ(preferred specification)を元にした反実仮想を複数
工程1と2で挙動がおかしい箇所があればコードのデバッグし、それでもおかしい場合は工程0の特定化を疑う。それでもおかしい場合は理論自体が不完全か、そもそも検証できるサンプルサイズではない。理想的には、工程1と2で使用される自作関数はデバッグと特定化の共通変更を考慮して共通のものであってほしいが、現実は実データと生成データのデータセット構造が異なるので、最低限の調整にとどめたい。
工程1と工程2は工程0が固定されたら、独立のPCで並行してコードを回せる。工程1.1と1.2.も、工程1が定まれば独立のPCで並行に回せる。工程2.1.も工程2が定まれば同様に独立のPCで並行に回せる。工程1と2は特定化以外は完全に独立なので、計算終了次第、該当章にレポートにすることができる。それぞれの工程が数日かかったりするので、できるだけ「物理的な」作業の並列化で効率化するのもいまだに大事。
単著の場合は、ひとまずこれが現在のベストプラクティス。指導教官からは「とにかくシンプルな特定化にこだわること」を何度も指摘されたので、最初から欲を出さず解けるところを広げていくのがよいのだろう。
共著の場合はタスクをどう割り振るかも影響してくる。以下は参考になる。
呼ばれてる気がするので答えます。現行のプロジェクトだと、構造推定:自分でほぼ全部やってる+RAにデータ取得などをお願いするx2、博士課程以上のスキルの人とタスク(推定、シミュレーションなど)ごとに分割x1、博士課程以上のスキルの人にほぼ全部やってもらっているx3、
— Kohei Kawaguchi (@mixingale) September 14, 2021
同級生どうしで構造推定やる時とかにどうすればいいのか最近,先生に聞いたことがあるんですけど,いくつかやり方があるだろうとのことでした.まず既存の推定手法(BLP)みたいなコードがどこにでもあるものを使うならデータクリーニングの分担がメインになるのでほぼ平等に分担できる.
— 似非 (@kDrjf853_3tna) September 13, 2021